大数据时代的数据引擎 Hive数据仓库与数据处理服务详解

在当今数据驱动的商业与科研环境中,大数据技术已成为核心基础设施。其中,Apache Hive作为一个构建在Hadoop之上的数据仓库工具,以其强大的数据处理能力和相对友好的使用体验,在企业级数据仓库构建和数据分析领域占据了重要地位。本文将系统介绍Hive数据仓库的核心概念、架构原理及其作为数据处理服务的关键角色。
一、Hive数据仓库:定义与核心价值
Apache Hive是一个开源的数据仓库框架,专为海量数据集(通常存储在Hadoop分布式文件系统HDFS中)的查询和管理而设计。其核心价值在于,它将复杂的MapReduce编程抽象化,允许用户使用类似SQL的查询语言(HiveQL或HQL)来处理数据,从而显著降低了大数据处理的技术门槛。对于熟悉传统关系型数据库和SQL的数据分析师与工程师而言,Hive提供了一个平滑过渡到大数据生态的桥梁。
Hive并非一个传统的在线事务处理(OLTP)数据库,而是一个典型的批处理导向的在线分析处理(OLAP)系统。它更适合用于数据挖掘、离线分析、报表生成等场景,而非高并发的实时交易。
二、Hive的架构与工作原理
Hive的架构清晰地将用户接口、元数据管理与查询执行分离开来:
- 用户接口:主要包括Hive命令行界面(CLI)、Web GUI(如Hue)以及通过JDBC/ODBC驱动连接的客户端工具。用户通过这些接口提交HiveQL查询。
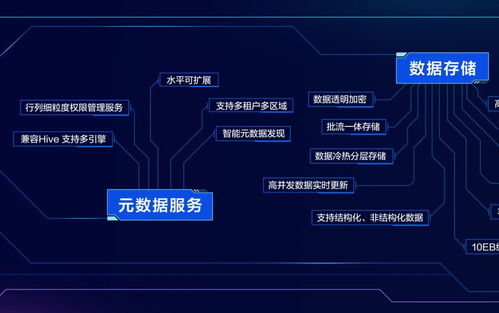
- 元数据存储(Metastore):这是Hive的“大脑”,通常使用独立的关系型数据库(如MySQL、PostgreSQL)来存储表结构、列类型、数据分区、文件路径等元数据。元数据与数据的物理存储分离,使得数据定义更加灵活。
- 查询编译器与执行引擎:当用户提交一条HQL语句后,Hive会对其进行解析、编译、优化,并最终生成一个可在Hadoop集群上执行的MapReduce、Tez或Spark作业(具体取决于配置的执行引擎)。
- Hadoop核心:Hive本身不存储数据,数据持久化在HDFS中。计算任务则由MapReduce、Tez或Spark等分布式计算框架执行,结果写回HDFS或直接返回给用户。
三、Hive作为数据处理服务的关键特性
- 表结构与数据模型:
- 内部表与外部表:内部表的数据生命周期由Hive管理,删除表时会同时删除HDFS上的数据;外部表仅管理元数据,删除表不影响底层数据,常用于关联已有数据文件。
- 分区与分桶:
- 分区:根据某一列(如日期
dt、地区region)的值将表数据物理分割到不同的HDFS目录下。查询时通过WHERE子句指定分区,可以避免全表扫描,极大提升查询效率。
- 分桶:根据哈希函数将数据分散到固定数量的文件中,常用于提升采样效率、优化特定类型的连接(JOIN)操作。
2. HiveQL:强大的查询语言:
HiveQL不仅支持标准的SQL查询(SELECT, JOIN, GROUP BY, ORDER BY等),还扩展了许多适合大数据场景的特性,如:
- 多表插入(Multi-Table Insert)、动态分区插入。
- 复杂的聚合函数、窗口函数(用于高级分析)。
- 用户自定义函数(UDF)、用户自定义聚合函数(UDAF)和用户自定义表生成函数(UDTF),允许用户用Java等语言扩展功能。
3. 多种文件格式与压缩:
Hive支持多种高效的列式存储格式,如ORC和Parquet。这些格式不仅压缩率高,节省存储空间,还支持谓词下推、延迟物化等优化,能大幅提升查询性能。配合Snappy、LZO等压缩算法,可以在I/O和CPU开销之间取得良好平衡。
4. 执行引擎的演进:
早期的Hive完全依赖MapReduce,延迟较高。现在,Hive支持将Tez或Spark作为执行引擎。Tez通过有向无环图(DAG)优化任务执行,减少了中间结果的落盘开销;Spark则利用内存计算,对于迭代式和交互式查询性能提升显著。这使Hive在保持批处理优势的也能适应更快的查询需求。
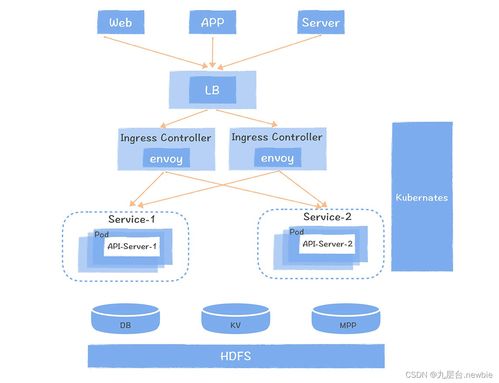
四、Hive在数据处理服务体系中的角色
在一个完整的企业级大数据平台中,Hive通常扮演着核心数据仓库和统一数据服务层的角色:
- 数据湖上的结构化视图:原始数据(日志、事务记录等)通过Flume、Sqoop、Kafka等工具摄入到HDFS或对象存储(数据湖)中。Hive通过定义外部表,为这些半结构化/非结构化数据提供了一层结构化的元数据抽象,使其能够被SQL便捷地访问。
- ETL(抽取、转换、加载)与数据加工:利用HiveQL强大的数据处理能力,可以编写复杂的调度作业(通常由Azkaban、Oozie等调度工具协调),完成数据的清洗、转换、聚合和维度建模,最终生成服务于不同业务线(如报表、用户画像、风险控制)的明细层、汇总层数据表。
- 即席查询与交互式分析:数据科学家和业务分析师可以通过BI工具(如Tableau、Superset)连接Hive,对处理后的数据层进行自助式的探索和分析。
- 机器学习与数据科学的数据源:处理后的高质量数据可以方便地导出,或直接通过Spark SQL等接口,为Spark MLlib、TensorFlow等机器学习框架提供训练和预测数据。
五、优势、挑战与未来展望
优势:易用性高(SQL接口)、可扩展性强(依托Hadoop横向扩展)、成本低廉(开源、可运行在廉价硬件上)、社区生态成熟。
挑战:默认情况下查询延迟较高(分钟级),不适合极低延迟的实时场景;需要精细的调优(如分区设计、SQL写法、参数配置)才能发挥最佳性能。
展望:随着计算存储分离架构、云原生数据仓库(如Snowflake、BigQuery)的兴起,Hive也在持续进化。例如,Hive on Spark、Hive LLAP(Live Long and Process)等项目旨在提供更快的交互式查询体验。Hive的元数据服务(Hive Metastore)已成为许多其他大数据组件(如Spark、Presto、Flink)的事实标准元数据目录,其作为大数据生态“粘合剂”的角色愈发重要。
###
总而言之,Apache Hive作为大数据领域经典且强大的数据仓库解决方案,通过将SQL的简洁性与Hadoop生态的可扩展性相结合,成功构建了一个高效、稳定、易用的企业级数据处理服务平台。尽管面临实时化挑战,但其在批处理、数据治理、大规模分析以及作为统一数据服务层方面的核心地位,在可预见的未来仍将不可替代。理解和掌握Hive,是深入大数据技术栈的关键一步。
如若转载,请注明出处:http://www.5p7fl8.com/product/70.html
更新时间:2026-06-19 14:29:48